
Kelpy Consensus
At Floating Forests, we get confronted with two issues a lot. First, how good is the data? A lot of scientists are still skeptical of citizen science (wrongly!) Second, many citizen scientists worry that they need to achieve a level of accuracy that would require near-pixel levels of zooming. We approach both of these issues with consensus classification – namely, that every image is seen by 15 people as soon as it’s noted that it has kelp in it. We can then build up a picture of kelp forests where, for each pixel, we note how many users select it as, indeed having kelp. You can read an initial entry about this here.
So, how does this pan out in the data I posted a few days back? Let’s explore, and I’ll link to code in our github repo for any who want to play along at home if you’re using R – I’d love to see things generated in other platforms!
The data is a series of spatial polygons, each one representing one level of consensus. After loading the data we can look at a single subject to see what consensus does.

I love this, as you can see both at the 1 threshold at least one person was super generous in selecting kelp. However, at the 10 threshold (unclear why we’re maxing at 10 here – likely nothing was higher!) super picky classifiers end up conflicting with each other so it looks like there’s no kelp here.
How does this play out over the entire coast? Let’s take a look with some animations. First, the big kahuna – the whole coast! Here are all of the classifications from 2008-2012 overlapping (I’ll cover timeseries another time).
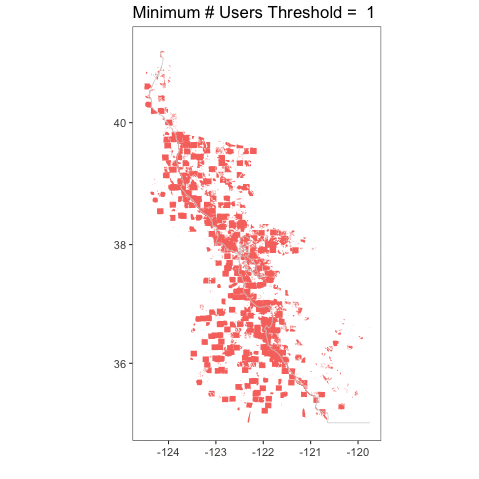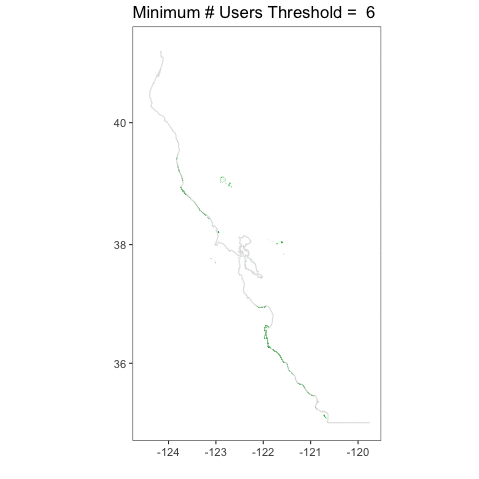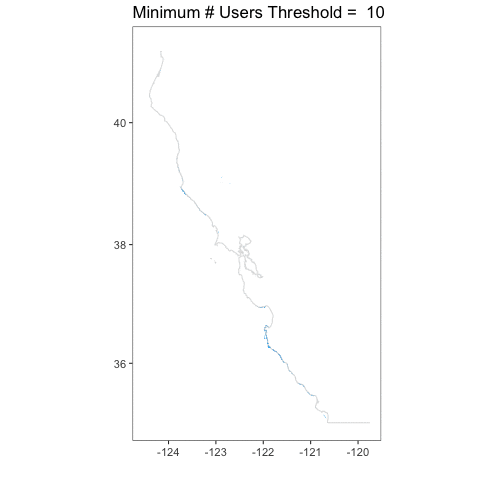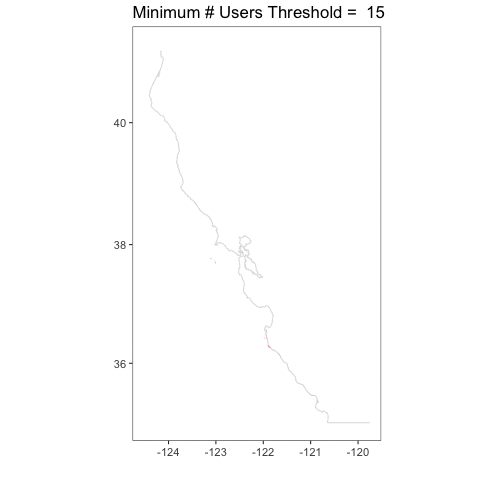
I love this, because you can really see how crazy things are at a single user, but then they tamp down very fast. You can also see, given that we have the whole coastline, how, well, coastal kelp is! Relative to the entire state, the polygons are not very large. It’s a bit hard to see.
Let’s look at the coastline north of San Francisco Bay, from Tomales to roughly Point Arena.
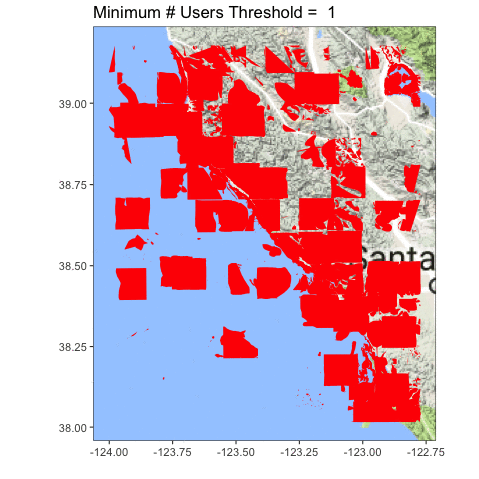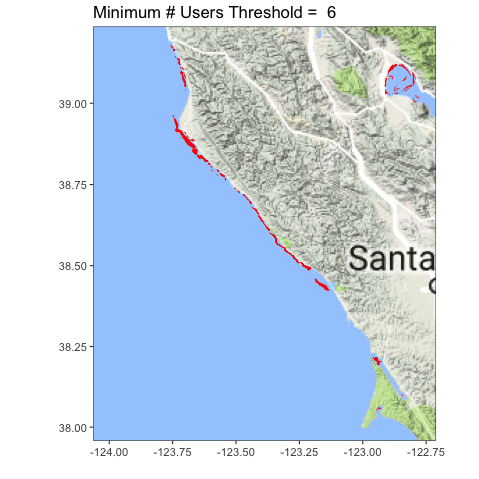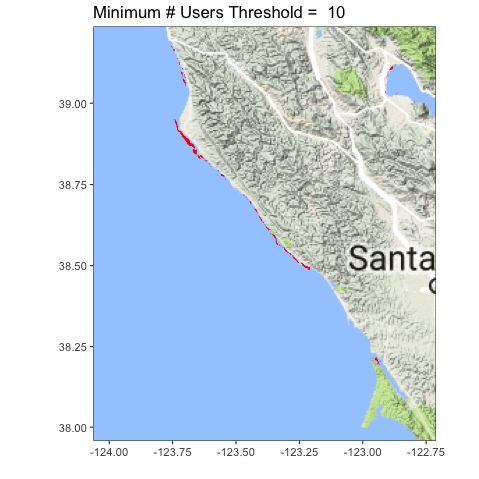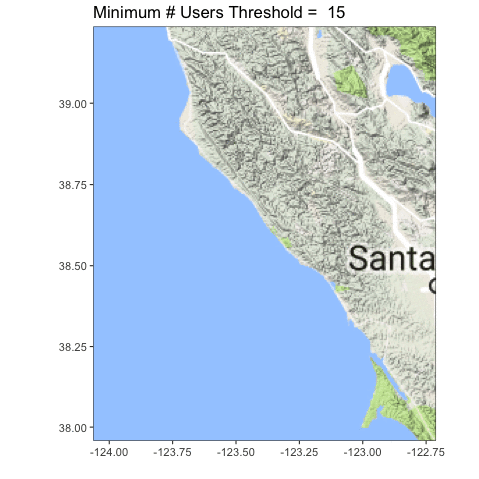
Definitely clearer. You can also see we accidentally served up some lake photos, and folk probably circled plankton blooms. Oops! Now the question becomes, what is the right upper threshold? Time (and some ongoing analysis which is suggesting somewhere between 6-8) will tell!
If you have ideas for other visualizations you want to see, queries for the data that you want us to make, or more, let us know in the comments! If you want to see some other visualizations we’ve been whipping up, see here!
3 responses to “Kelpy Consensus”
Leave a comment
Recent Comments
| jebyrnes on Does Citizen Science Consensus… | |
| padibby on Does Citizen Science Consensus… | |
| zuzayshish on Kelpy Consensus | |
| jebyrnes on Kelpy Consensus | |
| zuzayshish on Kelpy Consensus |

I soooo love this post! I was just wondering about what the differences among individual classifications are like. It is superuseful to see how the data actually looks on your end. Thanks, and keep posting 🙂 Cheers, Zuzi
LikeLike
So, these are just the consensuses. The individual classifications aren’t really in an easily usable format (they’re an intermediary to generating this file). We might change that in the future, though. It’s just a massive file! If there’s interest for it, though, I’ll make it a priority!
LikeLike
Oh, thanks for your reply. I haven’t notice it until now!
No need to change your priorities, these graphics above are good (or rather great) enough to satisfy my curiosity 🙂
LikeLike