
Coastlines of Floating Forests
Some of you have noted in earlier posts of this preliminary dataset that some classifications show up on land – particularly at low thresholds. This is likely due to some images being served up that, shouldn’t have been (we’ve fixed this in the new pipeline), and the zeal of some classifiers. Regardless, we can crop out those areas, as we know that there’s no real kelp there. But do to it, we need some very very good maps of the coastline. Fortunately, there’s a solution!
The Global Self-consistent, Hierarchical, High-resolution Geography Database is an incredible resource, with some coastline data files that are remarkable in their detail. The data is also, of course, huge. So, for anyone playing along at home, we’ve subsetting it down to a few files for you delectation. These are all in the common ESRI Shapefile format, but if folks want them otherwise, we’re happy to provide. Here’s what we’ve created for you. Click on the names of the areas below to download the zip files.
First, California
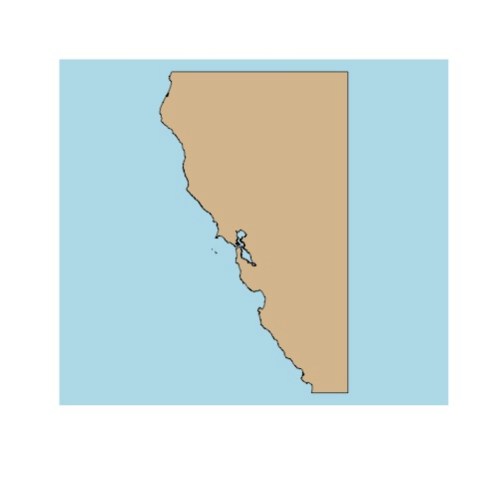
Then, Tasmania
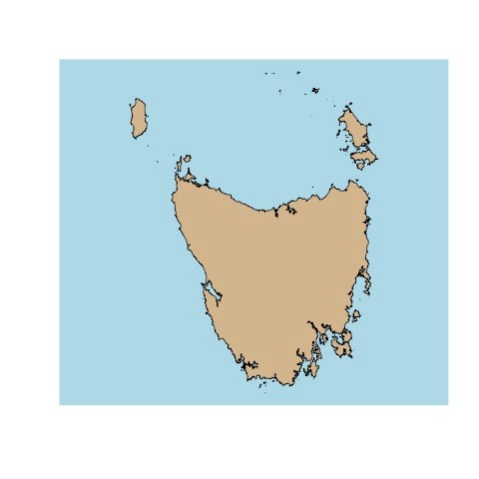
And last, the absolutely stunning Falkland Islands

When we used them for coastal cropping, they worked great – we’ll show some timeseries with cropped data next week!

Red areas are in the ocean, blue is on land.
Kelpy Consensus
At Floating Forests, we get confronted with two issues a lot. First, how good is the data? A lot of scientists are still skeptical of citizen science (wrongly!) Second, many citizen scientists worry that they need to achieve a level of accuracy that would require near-pixel levels of zooming. We approach both of these issues with consensus classification – namely, that every image is seen by 15 people as soon as it’s noted that it has kelp in it. We can then build up a picture of kelp forests where, for each pixel, we note how many users select it as, indeed having kelp. You can read an initial entry about this here.
So, how does this pan out in the data I posted a few days back? Let’s explore, and I’ll link to code in our github repo for any who want to play along at home if you’re using R – I’d love to see things generated in other platforms!
The data is a series of spatial polygons, each one representing one level of consensus. After loading the data we can look at a single subject to see what consensus does.

I love this, as you can see both at the 1 threshold at least one person was super generous in selecting kelp. However, at the 10 threshold (unclear why we’re maxing at 10 here – likely nothing was higher!) super picky classifiers end up conflicting with each other so it looks like there’s no kelp here.
How does this play out over the entire coast? Let’s take a look with some animations. First, the big kahuna – the whole coast! Here are all of the classifications from 2008-2012 overlapping (I’ll cover timeseries another time).
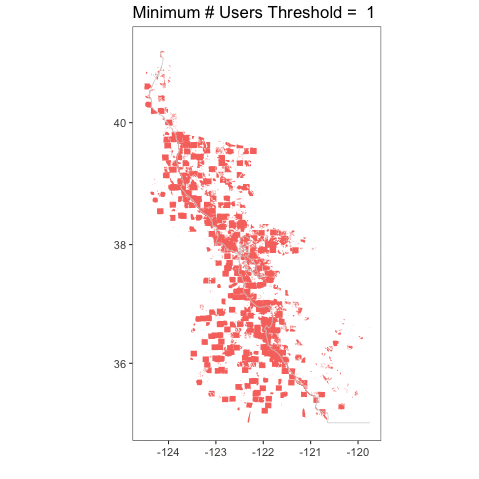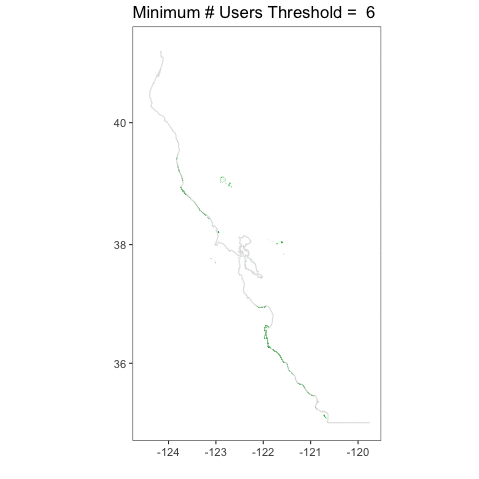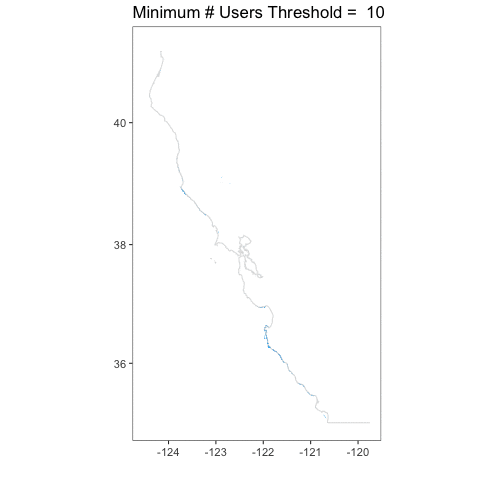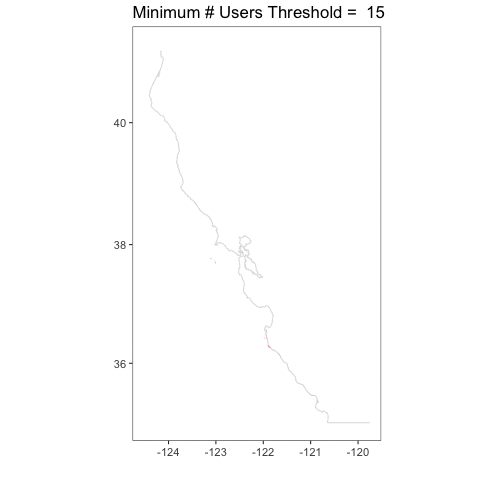
I love this, because you can really see how crazy things are at a single user, but then they tamp down very fast. You can also see, given that we have the whole coastline, how, well, coastal kelp is! Relative to the entire state, the polygons are not very large. It’s a bit hard to see.
Let’s look at the coastline north of San Francisco Bay, from Tomales to roughly Point Arena.
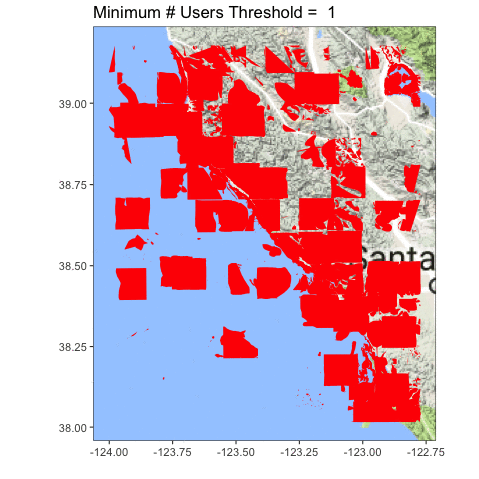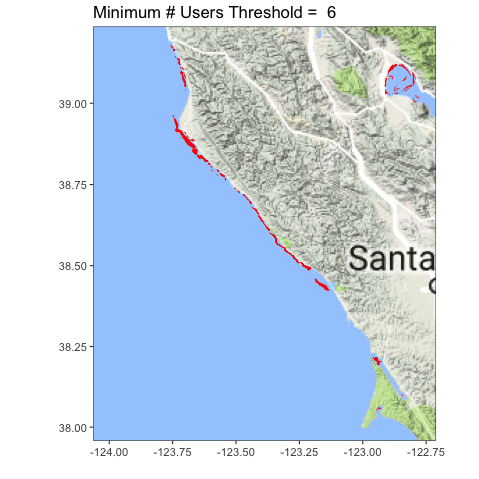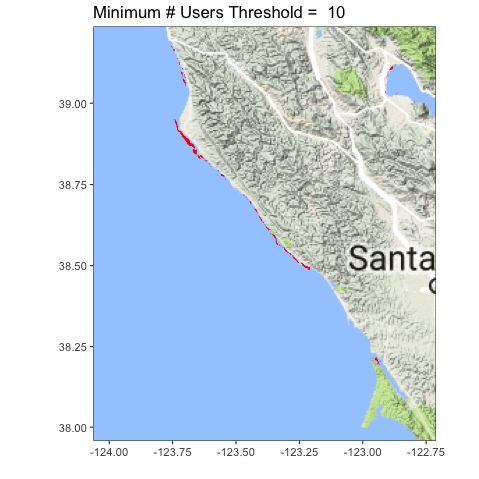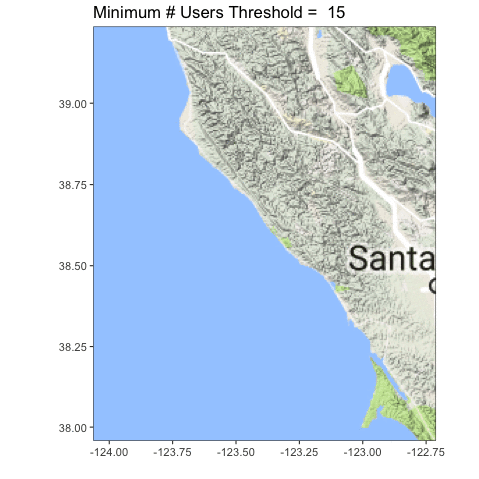
Definitely clearer. You can also see we accidentally served up some lake photos, and folk probably circled plankton blooms. Oops! Now the question becomes, what is the right upper threshold? Time (and some ongoing analysis which is suggesting somewhere between 6-8) will tell!
If you have ideas for other visualizations you want to see, queries for the data that you want us to make, or more, let us know in the comments! If you want to see some other visualizations we’ve been whipping up, see here!
Data from Floating Forests for YOU!
The day has come – we’re finalizing our data pipeline to return data to you, our citizen scientists! It’s been a twisty road, and we’re still tweaking, but we’ve begun to build some usable products for your delecation and exploration!
We want to know more from **you** about what you want and what is interesting for you to explore, so, today, I’m going to post some demo data for you to look at and give us feedback and comments on. This is a data file from our California project that consists of polygons for each kelp forest at different levels of user agreement on whether pixels are kelp or not. So, first, here’s the file in three formats (depending on what you want) (we can also add more if asked for)
SQLite Lat/Long Projection
RDS (native R format) Lat/Long Projection
RDS (native R format) UTM Projection (Zone 10)
You can do a lot with these in whatever GIS software is your preference, and if anyone has examples, we’d love to post them! For now, here’s a quick and dirty visualization of the whole shebang at the 6 users agreeing on a pixel per threshold (source.

Neat, huh? You can even see where something in one image was confusing (no kelp on land!) which now I’m *very* curious about.
So, what’s in this dataset? There’s a lot, but here are things most relevant to you
threshold – the number of users who agree on the pixels in a given polygon are kelp
zooniverse_id – the subject (i.e., tile) id of a given image, if you want to just look at a single image, subset to that id
scene – Individual Landsat “images” are called scenes. So, every subject that we served to users was carved out of a scene. You can look at a whole scene by subsetting on this column. For more about what a scene name means, see here
classification_count – number of users who looked at a given subject
image_url – to pull up the subject as seen on Floating Forests
scene_timestamp – when was an image taken by the satellite?
activated_at – when did we post this to Floating Forests?
There’s a lot of other info regarding subject corner geospatial locations. We might or might not trim this out in future versions, although for now it helps us locate missing data and see what has actually been sampled.
So, take a gander, enjoy, and if you have any comments, fire them off to us! This is just a sample, and there’s more to come!
Kelp Forest Heatmap: Nightvision Edition
It’s been a bit since I promised calibration info, but we’ve hit a minor (almost solved) projection issue in comparing our data to some gold-standard data we have. So, to stave off boredom while the real geographers on our team do the heavy lifting, I’ve been futzing about with making the generation of overall indices easier. I arrived at a neat solution using Spatial Grids in R that was much faster than switching back and forth between rasters. The biggest bonus is that the default plotting of results with color as number of people selecting an area is *purty!*
Or at least, I think so.
How does this kelp forest look to you?

Heatmap of Kelp Selection Overlap
A lot of what we’ll be working on to determine area of beds are heatmaps of users selecting a pixel as kelp. This sounds somewhat abstract, so I wanted to operationalize it for you with some images. Let’s start with a single image from Floating Forests chosen because it has been flagged as having kelp. It has 13 classifications, so, one more and it is ‘complete’ – unless we decide to lower the classification threshold. The image is

So, what would it look like if we overlaid all of the outlines of users outlining kelp from the other day on the image?

You can see, to some extent, folk circling the same areas, and their varying degrees of specificity. What does this result in if we want a heatmap of number of users selecting each pixel on which to do our analysis? Well, here you go!
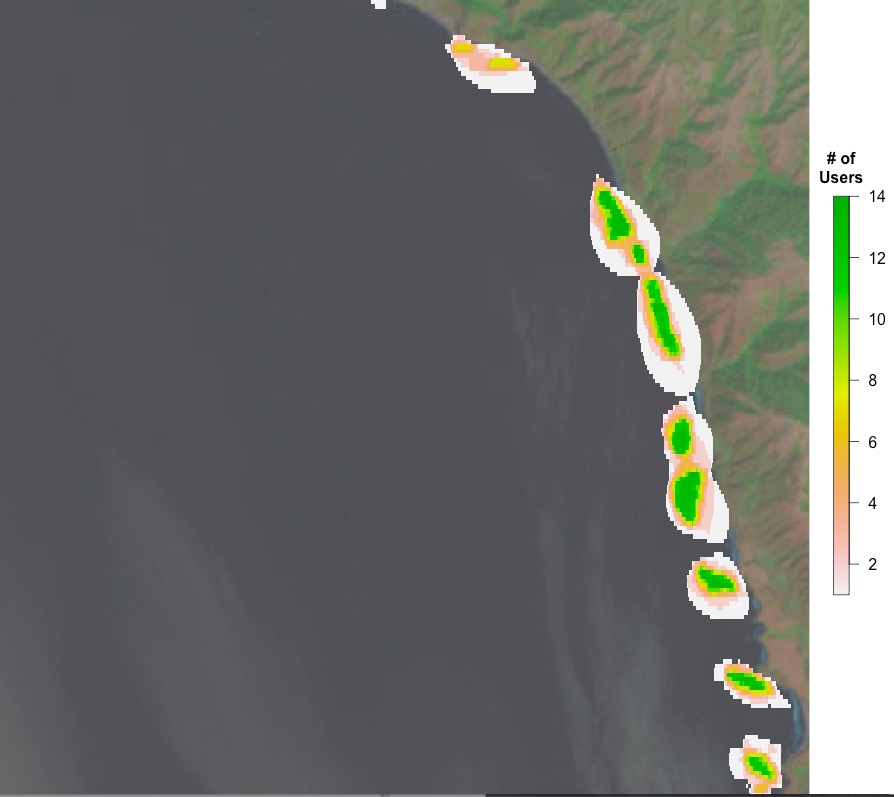
Next time, a more quantitative look.
Variation in Kelp Selection is Beautiful
For the next post or three, I’m going to talk about what I see when I look at the data from one image. In the coming weeks, I hope to get at putting together bigger spatial or temporal results. But for the moment, I’m going to begin with what we see when we look at user classifications of one image. I’m going to begin with something beautiful – human variation.
This is the variability from person to person that we see in circling the same set of beds. I just find it striking and lovely.


Recent Comments